更新主题为黑色风格
本博客使用博主自制主题: Fika theme for Hugo
我个人本身夜间活动较多,而之前的主题背景颜色偏白,在夜晚的时候偶尔会让我眼睛有被闪瞎的感觉。
遂决定把主题更改为黑暗模式风格,目前已经更新完成。风格颜色参考了 GitHub
本博客使用博主自制主题: Fika theme for Hugo
我个人本身夜间活动较多,而之前的主题背景颜色偏白,在夜晚的时候偶尔会让我眼睛有被闪瞎的感觉。
遂决定把主题更改为黑暗模式风格,目前已经更新完成。风格颜色参考了 GitHub
Hexo 作为博客引擎长期以来使用还是非常方便的。
但由于其本身是基于nodejs和npm,其中使用到的各种npm库的嵌套依赖关系十分杂乱。有可能因為某个子包出BUG而导致引用了该包的所有库均出现各种问题。
已经受够了长期以来明明没有更新文章,但本地却需要保持各种npm包为较新的版本所花费的额外精力。
所以干脆直接更换为基本没有三方依赖的 Hugo,并自己重写了自己使用的主题。
如果有Hugo用户恰好喜欢这款主题,欢迎使用: Fika theme for Hugo
hexo_to_hugo.py
# pip install yaml
# usage: python hexo_to_hugo.py
import os
import re
import yaml
# fill default date with this GMT zone
GMT = '+08:00' # for SG time zone
HEADER_FLAG = '---\n'
def file_lines(fname):
f = open(fname, "r", encoding='utf-8')
ret = f.readlines()
f.close()
return ret
def parser_head_lines(lines: list[str]) -> list[str]:
header_lines = list[str]([])
in_header = False
for i, line in enumerate(lines):
if line == HEADER_FLAG:
if not in_header:
in_header = True
continue
else: # header end flag founded
break
if in_header:
header_lines.append(line)
return header_lines
def revise_header_flag(lines):
revised = False
if len(lines) == 0:
return lines, revised
if lines[0] == HEADER_FLAG:
return lines, revised
lines.insert(0, HEADER_FLAG)
revised = True
return lines, revised
def revise_header_content(header_lines: list[str]):
revised = False
for i, line in enumerate(header_lines):
# date line
rdate = re.search(r'date:\s+(\d{4})-(\d{2})-(\d{2}) (\d{2}):(\d{2}):(\d{2})', line, re.M)
if rdate: # date line for need revise to TZ format
header_lines[i] = f'date: {rdate.group(1)}-{rdate.group(2)}-{rdate.group(3)}T{rdate.group(4)}:{rdate.group(5)}:{rdate.group(6)}{GMT}\n'
revised = True
# revise for tags and categories to type list
header_revised = False
header = yaml.safe_load(''.join(header_lines))
if 'categories' in header: # make sure categories are type list
categories = header['categories']
if not isinstance(categories, list):
if categories == None:
header['categories'] = []
else:
header['categories'] = [categories]
header_revised = True
if 'tags' in header: # make sure tags are type list
tags = header['tags']
if not isinstance(tags, list):
if tags == None:
header['tags'] = []
else:
header['tags'] = [tags]
header_revised = True
if header_revised:
header_lines = yaml.dump(header, default_flow_style=False, allow_unicode=True).splitlines(True)
revised = True
return header_lines, revised
def save_file(fname, lines):
f = open(fname, 'w', encoding='utf-8', newline='\n')
f.writelines(lines)
f.close()
def main():
HEADER_FLAG = '---\n'
print('--- starting revise for posts... ---')
POST_PATH = os.path.join('content', 'posts')
posts_count = 0
header_flag_revised_count = 0
header_revised_count = 0
files = os.listdir(POST_PATH)
for fname in files:
fullpath = os.path.join(POST_PATH, fname)
if not os.path.isfile(fullpath):
continue
lines = file_lines(fullpath)
lines, header_flag_revised = revise_header_flag(lines)
if header_flag_revised:
print(f'revised header flag: {fname}')
header_flag_revised_count += 1
header_lines = parser_head_lines(lines)
body_lines = lines[len(header_lines)+2:] # skip two header flag lines
header_lines, header_revised = revise_header_content(header_lines)
if header_revised:
print(f'revised date: {fname}')
header_revised_count += 1
if header_flag_revised or header_revised:
print(f'save revised file: {fname}')
header_lines.insert(0, HEADER_FLAG)
header_lines.append(HEADER_FLAG)
save_file(fullpath, header_lines + body_lines)
posts_count += 1
print(f'--- revise over. ---\nposts: {posts_count}\nheader flag revised: {header_flag_revised_count}\nheader revised: {header_revised_count}')
if __name__ == "__main__":
main()
使用方法: 进入 Hugo 站点根目录运行
python hexo_to_hugo.py
脚本下载: hexo_to_hugo.py
最近用 Github 比较频繁,无意间点开 GitHub Pages 的代码库时发现一个大大的 Dependabot alerts 顶在上面
点开后发现最大的一个警告就是这个:
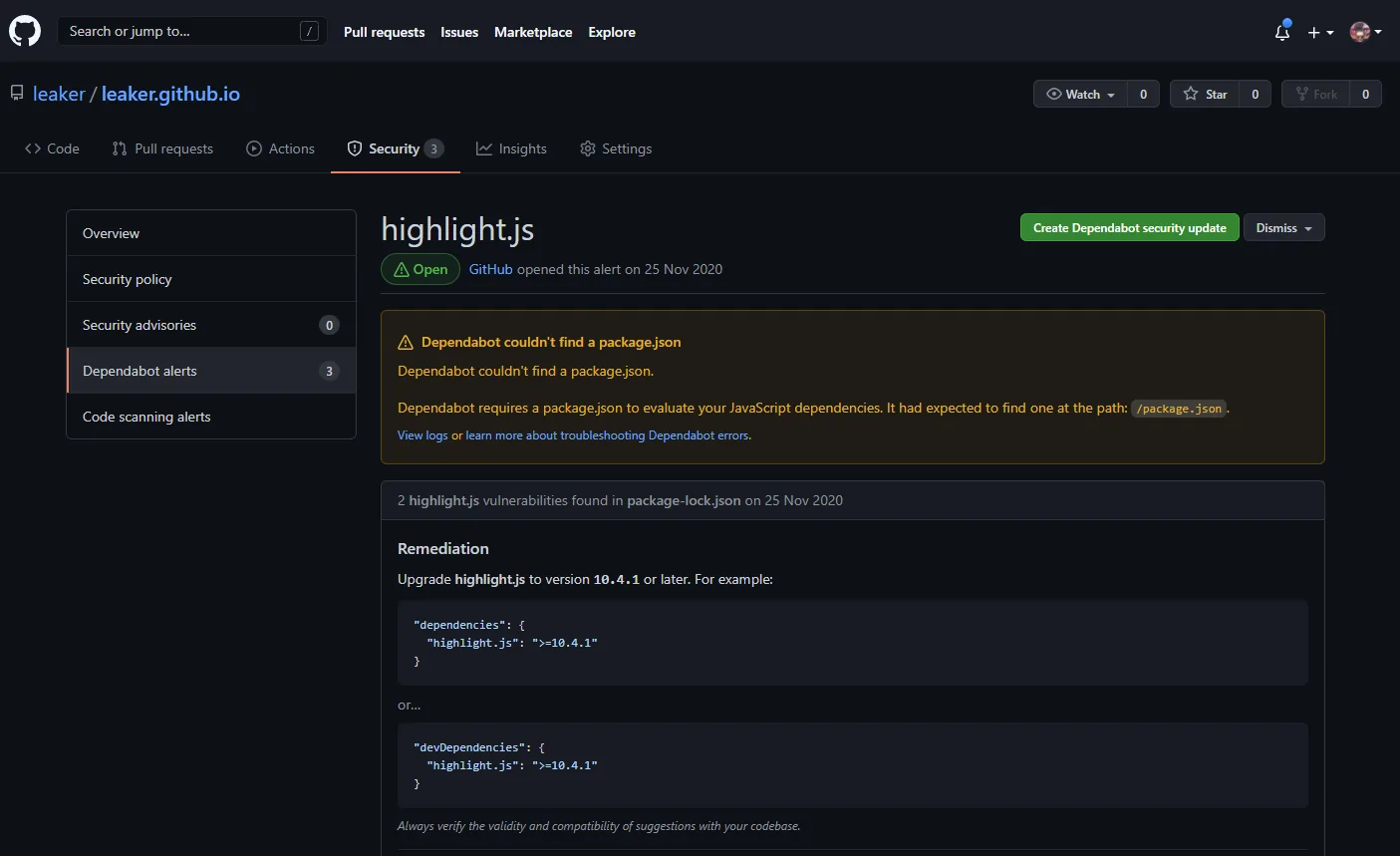
顺着这个 dependencies 一路追查发现是 hexo-prism-plugin 这个插件使用的 由于该插件太久没更新,而且发现 hexo.io 最新版本已经集成了 prism 的代码高亮功能 所以更新 Hexo 版本并启用自带的代码高亮功能应该就可以解决了
prismjs:
enable: true
preprocess: true
line_number: true
tab_replace: ' '
突然心血来潮想把自己的笔记用阿里云CDN加速一下,但域名就需要备案。 而我本身的域名不想因为备案就迁回到国内的域名服务商(这里有一段在国内购买域名的黑历史) 所以干脆重新购买了一个新的域名 www.kaij.cn 用来备案
直接在阿里云上面买域名可以不用等迁移的时间 顺便一说,使用阿里云的快速备案服务来备案真的太方便了
但备案的时候遇到了一点小问题,之前起的博客名称无法用于备案,收到了提示:
网站名称“ 李略帅 ”不合格,个人网站名称不能涉及到行业、企业等信息,且个人网站名称请勿涉及个人姓名、地名,请不要用纯数字或字母组成,不能包含特殊符号,不能使用成语;网站名称请使用3个以上汉字命名,请不能使用XXX个人空间、资讯、网站、网络、网址、爱好者、作品展示、工作室、平台、主页、热线、社团、导航这种的格式命名;网站名称中不能带有博客、论坛、在线、社区、交流等字样,若要带有此类信息,需提交前置审批文;具体命名要求请参考专区文章:https://help.aliyun.com/knowledge_detail/36948.html#title-lhm-b1g-ehx
按照这些要求来说 XXX的个人博客、XXX的个人主页 这类肯定是不行了。由于也禁止使用成语,所以想翻翻字典来找个合适的名字也不行。 想来想去似乎只有一句话类型的语言不容易触犯到这些规则。而经常有一些日系的电视电影起的名字我觉得就非常有创意。 刚好之前看过日本由百分之九十九的码农都会沉浸在她笑容里的公民老婆 Gakki(日文原名:新垣 結衣) 出演的两部剧:
剧集给我的印象非常深刻。所以抱着试一试的心态填了一个,结果认证了我的猜想。像这样的一句话通常不会触犯到起名规则,可以顺利通过审核。
所以现在我的笔记多出了一个用于国内用户快速访问的通道 https://www.kaij.cn 国外用户依然可以使用之前的域名继续访问 https://www.leelib.com
毕竟出身一名程序员就不能少了使用 GitHub Pages 这样优秀的服务创建一个属于自己的小港湾,去记录一些生活中的点点滴滴。 (๑•̀ㅂ•́)و✧
之前的高亮插件支持的语言比较少,而且效果不是特别理想。特进行了一次修整,内容如下:
李略帅 名字肿么样?
先改了再说,好让搜索引擎方便收集。后面填内容。
以上!